Instant Connection for Pixel Streaming
— New Feature Automated Setup

A Step-by-Step Guide to Running DeepSeek-R1 on Low-End Devices & Cloud
A Step-by-Step Guide to Running DeepSeek-R1 on Low-End Devices & Cloud
ComputerPerformance
A Step-by-Step Guide to Running DeepSeek-R1 on Low-End Devices & Cloud
Table of Contents
In the rapidly evolving field of artificial intelligence, DeepSeek-R1 has emerged as a groundbreaking model renowned for its advanced reasoning capabilities. Developed to excel in complex tasks such as mathematical problem-solving, coding assistance, and natural language inference, DeepSeek-R1 offers robust performance at a fraction of the typical computational cost. Its efficiency and open-source nature have positioned it as a formidable alternative to existing AI models.
To harness the full potential of DeepSeek-R1, access to high-performance computing resources is essential. This is where Vagon comes into play. Vagon provides cloud-based desktops that deliver the power of top-tier hardware without the need for physical infrastructure. With Vagon, users can run resource-intensive applications like DeepSeek-R1 seamlessly, benefiting from scalable performance, high-speed internet connectivity, and the flexibility to work from any device.
This guide aims to provide a comprehensive walkthrough for setting up and running DeepSeek-R1 on Vagon's cloud desktops. Whether you're a researcher, developer, or AI enthusiast, this resource will equip you with the knowledge to effectively leverage Vagon's cloud solutions for your DeepSeek-R1 projects.
#1: Understanding DeepSeek-R1
DeepSeek-R1 is an open-source AI model designed to excel in complex reasoning tasks. Its architecture employs a Mixture of Experts framework, activating only the necessary parameters during processing, which enhances computational efficiency. This design enables the model to perform tasks such as mathematical problem-solving, code generation, and logical inference with high accuracy.

A notable feature of DeepSeek-R1 is its training methodology, which emphasizes reinforcement learning to develop reasoning capabilities. This approach allows the model to autonomously discover and refine reasoning strategies, reducing reliance on large-scale human-annotated data. The model's open-source nature, distributed under the MIT license, grants researchers and developers the freedom to inspect, modify, and integrate it into various applications, fostering innovation and customization.
DeepSeek-R1 has gained popularity in the AI and machine learning communities due to its advanced reasoning capabilities and cost-effectiveness. Its performance in tasks requiring logical inference and problem-solving makes it a valuable tool for developers and researchers aiming to implement sophisticated AI solutions without incurring substantial costs.
#2: Understanding Vagon's Cloud Desktops
Vagon's cloud desktops are a game-changer for anyone needing high-performance computing without the hassle of maintaining expensive hardware. Unlike serverless GPUs, which can be limiting for interactive work like iterative development or multitasking, Vagon gives you a full desktop environment in the cloud. It feels like using your local machine, but with the kind of power you’d expect from a cutting-edge data center.
Here’s why people love Vagon:
Unmatched Performance: Vagon desktops are packed with NVIDIA GPUs and Intel CPUs, so you’re ready to tackle demanding tasks like training AI models, running simulations, or handling large datasets without breaking a sweat.
Ultimate Flexibility: Need more power? Scale up. Working on something lighter? Scale down. With customizable configurations, you only use the resources you need. Whether you’re fine-tuning a neural network or experimenting with DeepSeek-R1, Vagon adapts to your workload.
Anywhere, Anytime Access: Imagine starting a project on your laptop, picking it up later on your tablet, and finishing it off from anywhere with an internet connection. With Vagon, your high-performance desktop is always with you.
What about pricing?
Vagon keeps it simple and budget-friendly. You pay for what you use. For example, the "Spark" plan is perfect for moderate tasks at $1.67 per hour, while the powerhouse "Lava" configuration, great for intensive workloads, is $11.97 per hour. This flexibility means you can balance performance with your budget.

In short, Vagon isn’t just another cloud computing service. It’s a tool designed for creators, developers, and AI enthusiasts who need power, convenience, and control—all rolled into one.
#3: How to Setup and Run DeepSeek-R1 on Low-End Device or Vagon
This guide works the same whether you’re on a local machine or a Vagon cloud desktop. If you’re using Vagon, simply follow these steps inside your Vagon environment.
Ensure you've registered to Vagon, selected a performance plan (starting with "Planet" or "Spark" is recommended), and connected to your cloud computer.
#3.1: Download llama.cpp Binaries
Go to this release link.
Download the ZIP file and extract it to a convenient location—for example, C:\llama.
#3.2: Download DeepSeek-R1 8-bit Model
Visit DeepSeek-R1-Distill-Llama-8B-GGUF on Hugging Face.
From the Files sidebar, choose an 8-bit variant (e.g.,
DeepSeek-R1-Distill-Llama-8B-Q8_0.gguf) and click Download.Place the downloaded
.gguffile in a suitable folder—for example:C:\llama\models
Tip: You can use different quantization levels (Q4, Q5, Q8, etc.), but 8B Q8_0 offers a good balance of speed and thorough responses.
#3.3: Run DeepSeek-R1 from Command Line
Open a terminal (PowerShell, Command Prompt, etc.) and navigate to your llama.cpp folder:
cd C:\llama
Launch the model in CLI mode:#4: Installing Ollama and Downloading DeepSeek-R1
llama-cli.exe -m .\models\DeepSeek-R1-Distill-Llama-8B-Q8_0.gguf -ngl 33
-mpoints to the model file.
-ngl 33is an example GPU-layer setting, which offloads 33 layers to the GPU for faster inference.
With Vagon’s NVIDIA GPU support, you can directly leverage GPU acceleration. Just ensure you’ve selected a plan with sufficient GPU resources and the above command will automatically use the GPU to speed up your DeepSeek-R1 model.
Type your prompts directly in the CLI to interact with DeepSeek-R1.
#3.4: Setup Optional Web Interface
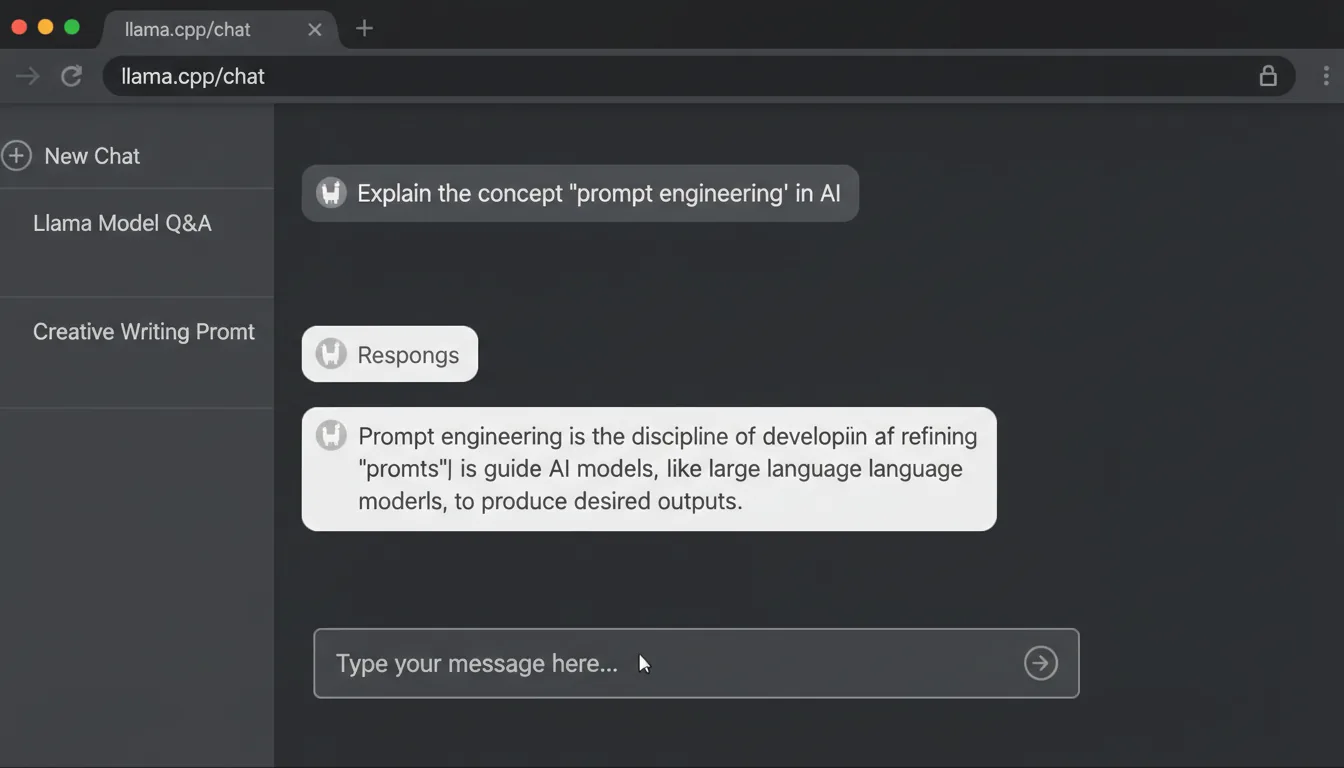
If you prefer a web-based interface in your browser:
Run the llama.cpp server:
llama-server.exe -m .\models\DeepSeek-R1-Distill-Llama-8B-Q8_0.gguf -ngl 33 --port 8080Open your browser and go to http://localhost:8080.
Start chatting with DeepSeek-R1 through the web UI.
For additional details on flags, performance tweaks, or other advanced usage, visit the llama.cpp GitHub page.
If you’d like to try the full (non-quantized) DeepSeek-R1 model, visit https://chat.deepseek.com/ and select “DeepThink (R1).”

By following these steps, you'll have DeepSeek-R1 running on your Vagon cloud desktop, providing a powerful AI toolset accessible from anywhere.
If you experience any issues, such as lagging or slower-than-expected performance while running DeepSeek-R1, it may be due to the resource requirements of your task. You can easily scale up to a higher performance tier on Vagon to access more powerful GPUs, additional CPU cores, and increased memory. Upgrading ensures smoother operation and optimal performance for resource-intensive workloads. Adjusting your plan can be done directly within your Vagon account settings for a seamless transition.
#6: Comparing DeepSeek-R1 on Serverless GPUs, Vagon Cloud Desktops, and Local Machines
When deciding where to run DeepSeek-R1, the choice of computing environment impacts performance, flexibility, and your overall workflow. Here’s a comparison of serverless GPUs, Vagon Cloud Desktops, and local machines—with an emphasis on why Vagon stands out as the optimal choice.

1. Serverless GPUs
Serverless GPUs, such as those offered by AWS Lambda or Google Cloud Functions, are designed for specific, short-term tasks. They are highly cost-efficient because you only pay for the resources you use, making them ideal for quick, one-off workloads. Additionally, serverless GPUs are fully managed by the provider, which eliminates the need for maintenance or manual server management.
However, serverless GPUs lack flexibility and are not suitable for iterative workflows or persistent environments. This limitation can make them challenging to use for tasks like developing AI models or running complex simulations. Furthermore, they are restrictive when it comes to running additional software or tools, such as code editors or AI code review tools, which are essential for holistic workflows. The setup process can also be complicated, as configuring environments and dependencies for each task often requires significant effort and expertise.
2. Vagon Cloud Desktops
Vagon Cloud Desktops provide a revolutionary approach by offering a high-performance, persistent environment that feels like your local machine but with significantly more power. One of their standout features is the ability to create a holistic workflow. Unlike serverless GPUs, Vagon allows you to seamlessly run additional tools like Visual Studio, Jupyter Notebooks, Excel, MATLAB, Blender, Unity, Unreal Engine, and even productivity apps like Slack or Google Chrome. This flexibility enables you to switch between tasks—such as running DeepSeek-R1 and analyzing results in Excel or coding in Visual Studio—without any interruptions.
The experience is akin to using a fully equipped Windows desktop, where you can install and manage software just as you would on a physical machine. Vagon also delivers unparalleled performance by letting you scale your resources on demand to handle anything from AI training to video rendering or 3D simulations. Furthermore, its accessibility from any device with an internet connection ensures you can work from anywhere, whether you're on a laptop, tablet, or smartphone. With no need to manage hardware or infrastructure, Vagon makes the process seamless and user-friendly.
The only notable downside of Vagon cloud desktops is their dependency on a stable internet connection. If your connection is unreliable, it may impact your experience, especially during high-intensity workloads.
3. Local Machines
Running DeepSeek-R1 on a local machine offers the advantage of low latency, as it eliminates any reliance on network connections. This means that responses and computations are immediate, ensuring smooth and uninterrupted performance. Additionally, local machines give you complete control over your setup, allowing you to configure hardware and software exactly as needed for your specific tasks.
However, the performance of a local machine is inherently limited by its hardware specifications. If your system lacks a powerful GPU, sufficient memory, or a fast processor, it may struggle to handle resource-intensive tasks such as AI model inference or 3D rendering. Building or upgrading a machine capable of running such tasks efficiently can also be prohibitively expensive, as high-end GPUs and components come with significant upfront costs. Lastly, local machines lack built-in scalability; once you hit the limits of your hardware, you cannot dynamically upgrade or expand resources to meet the demands of more complex projects.
Why Vagon Stands Out
Unlike serverless GPUs or local machines, Vagon offers a complete, holistic experience. You’re not limited to running just DeepSeek-R1; you can seamlessly integrate all your favorite tools into your workflow. For example:
Use Visual Studio to edit code.
Run Excel to analyze your results.
Use MATLAB or Jupyter Notebooks for advanced data analysis.
Vagon’s ability to combine powerful cloud computing with the familiarity of a local machine gives you a flexible, all-in-one workspace that no other solution can match.
If your project requires only short, simple tasks, serverless GPUs can be a budget-friendly option. Local machines are viable if you have powerful hardware and prefer offline access. However, Vagon cloud desktops stand out as the superior choice for running DeepSeek-R1 and beyond, offering:
Scalability for resource-heavy tasks.
A persistent, high-performance desktop environment.
Integration with your favorite tools for a holistic, streamlined workflow.
With Vagon, you don’t just get the power to run DeepSeek-R1—you gain a versatile, professional-grade workspace that adapts to all your needs. Whether it’s AI, design, engineering, or productivity, Vagon empowers you to work smarter, faster, and better.
Conclusion
Whether you’re a developer, researcher, or enthusiast, Vagon makes it easy to set up and run resource-intensive models like DeepSeek-R1 without the need for expensive hardware.
Vagon desktops are just like your local machine but with top-tier performance, allowing you to run not only AI tools but also your favorite apps with ease. From engineering, coding and simulation software like CAD tools and Visual Studio Code to creative apps like Blender, After Effects, Unreal Engine, Unity, and more, Vagon handles them all seamlessly.
With options to use the command-line interface or an intuitive web-based UI, you can tailor your workflow to your preferences. And if your projects demand more power, Vagon’s scalable performance tiers ensure you’re always equipped for the task at hand.
So, take the leap, explore, and unlock the full potential of these powerful tools and applications from anywhere in the world.
Frequently Asked Questions (FAQ)
1. What is DeepSeek-R1, and why is it popular?
DeepSeek-R1 is an advanced AI model designed for complex reasoning tasks like coding assistance, mathematical problem-solving, and natural language inference. Its open-source nature, efficient architecture, and cost-effectiveness make it a popular choice among researchers and developers looking for powerful AI solutions.
2. What are the hardware requirements for running DeepSeek-R1 locally?
To run DeepSeek-R1 locally, your machine needs a high-performance GPU (e.g., NVIDIA RTX 3090 or higher), at least 16 GB of RAM (32 GB recommended), and sufficient disk space for the model files. A multi-core CPU will also help improve performance.
3. Can DeepSeek-R1 be run on a CPU instead of a GPU?
Yes, but running DeepSeek-R1 on a CPU will significantly slow down its performance, especially for larger models. GPUs are highly recommended for resource-intensive tasks like training and inference due to their parallel processing capabilities.
4. Can I run DeepSeek-R1 on serverless GPUs?
Yes, but serverless GPUs, like those on AWS or Google Cloud, are generally designed for task-specific workloads. You’ll need to set up the environment each time you run the model, which can be tedious. Persistent environments, like cloud desktops, are more user-friendly for iterative workflows.
5. What is the difference between running DeepSeek-R1 on CLI and Web UI?
Command-Line Interface (CLI): Efficient for users comfortable with terminal commands. It’s faster and requires fewer resources.
Web UI: Offers a graphical interface that makes it easier to input prompts, tweak settings, and visualize outputs. It’s great for those who prefer an interactive experience.
6. Can I use multiple models with DeepSeek-R1?
Yes, you can download and switch between different models in the llama.cpp directory. Update the model path in your commands to use the desired model file.
7. How much disk space does DeepSeek-R1 require?
The disk space required depends on the size of the model you are using. For instance, the 4-bit quantized DeepSeek-R1 model file can range from 10 GB to 50 GB. Ensure you have enough free space before downloading the model.
In the rapidly evolving field of artificial intelligence, DeepSeek-R1 has emerged as a groundbreaking model renowned for its advanced reasoning capabilities. Developed to excel in complex tasks such as mathematical problem-solving, coding assistance, and natural language inference, DeepSeek-R1 offers robust performance at a fraction of the typical computational cost. Its efficiency and open-source nature have positioned it as a formidable alternative to existing AI models.
To harness the full potential of DeepSeek-R1, access to high-performance computing resources is essential. This is where Vagon comes into play. Vagon provides cloud-based desktops that deliver the power of top-tier hardware without the need for physical infrastructure. With Vagon, users can run resource-intensive applications like DeepSeek-R1 seamlessly, benefiting from scalable performance, high-speed internet connectivity, and the flexibility to work from any device.
This guide aims to provide a comprehensive walkthrough for setting up and running DeepSeek-R1 on Vagon's cloud desktops. Whether you're a researcher, developer, or AI enthusiast, this resource will equip you with the knowledge to effectively leverage Vagon's cloud solutions for your DeepSeek-R1 projects.
#1: Understanding DeepSeek-R1
DeepSeek-R1 is an open-source AI model designed to excel in complex reasoning tasks. Its architecture employs a Mixture of Experts framework, activating only the necessary parameters during processing, which enhances computational efficiency. This design enables the model to perform tasks such as mathematical problem-solving, code generation, and logical inference with high accuracy.
A notable feature of DeepSeek-R1 is its training methodology, which emphasizes reinforcement learning to develop reasoning capabilities. This approach allows the model to autonomously discover and refine reasoning strategies, reducing reliance on large-scale human-annotated data. The model's open-source nature, distributed under the MIT license, grants researchers and developers the freedom to inspect, modify, and integrate it into various applications, fostering innovation and customization.
DeepSeek-R1 has gained popularity in the AI and machine learning communities due to its advanced reasoning capabilities and cost-effectiveness. Its performance in tasks requiring logical inference and problem-solving makes it a valuable tool for developers and researchers aiming to implement sophisticated AI solutions without incurring substantial costs.
#2: Understanding Vagon's Cloud Desktops
Vagon's cloud desktops are a game-changer for anyone needing high-performance computing without the hassle of maintaining expensive hardware. Unlike serverless GPUs, which can be limiting for interactive work like iterative development or multitasking, Vagon gives you a full desktop environment in the cloud. It feels like using your local machine, but with the kind of power you’d expect from a cutting-edge data center.
Here’s why people love Vagon:
Unmatched Performance: Vagon desktops are packed with NVIDIA GPUs and Intel CPUs, so you’re ready to tackle demanding tasks like training AI models, running simulations, or handling large datasets without breaking a sweat.
Ultimate Flexibility: Need more power? Scale up. Working on something lighter? Scale down. With customizable configurations, you only use the resources you need. Whether you’re fine-tuning a neural network or experimenting with DeepSeek-R1, Vagon adapts to your workload.
Anywhere, Anytime Access: Imagine starting a project on your laptop, picking it up later on your tablet, and finishing it off from anywhere with an internet connection. With Vagon, your high-performance desktop is always with you.
What about pricing?
Vagon keeps it simple and budget-friendly. You pay for what you use. For example, the "Spark" plan is perfect for moderate tasks at $1.67 per hour, while the powerhouse "Lava" configuration, great for intensive workloads, is $11.97 per hour. This flexibility means you can balance performance with your budget.
In short, Vagon isn’t just another cloud computing service. It’s a tool designed for creators, developers, and AI enthusiasts who need power, convenience, and control—all rolled into one.
#3: How to Setup and Run DeepSeek-R1 on Low-End Device or Vagon
This guide works the same whether you’re on a local machine or a Vagon cloud desktop. If you’re using Vagon, simply follow these steps inside your Vagon environment.
Ensure you've registered to Vagon, selected a performance plan (starting with "Planet" or "Spark" is recommended), and connected to your cloud computer.
#3.1: Download llama.cpp Binaries
Go to this release link.
Download the ZIP file and extract it to a convenient location—for example, C:\llama.
#3.2: Download DeepSeek-R1 8-bit Model
Visit DeepSeek-R1-Distill-Llama-8B-GGUF on Hugging Face.
From the Files sidebar, choose an 8-bit variant (e.g.,
DeepSeek-R1-Distill-Llama-8B-Q8_0.gguf) and click Download.Place the downloaded
.gguffile in a suitable folder—for example:C:\llama\models
Tip: You can use different quantization levels (Q4, Q5, Q8, etc.), but 8B Q8_0 offers a good balance of speed and thorough responses.
#3.3: Run DeepSeek-R1 from Command Line
Open a terminal (PowerShell, Command Prompt, etc.) and navigate to your llama.cpp folder:
cd C:\llama
Launch the model in CLI mode:#4: Installing Ollama and Downloading DeepSeek-R1
llama-cli.exe -m .\models\DeepSeek-R1-Distill-Llama-8B-Q8_0.gguf -ngl 33
-mpoints to the model file.
-ngl 33is an example GPU-layer setting, which offloads 33 layers to the GPU for faster inference.
With Vagon’s NVIDIA GPU support, you can directly leverage GPU acceleration. Just ensure you’ve selected a plan with sufficient GPU resources and the above command will automatically use the GPU to speed up your DeepSeek-R1 model.
Type your prompts directly in the CLI to interact with DeepSeek-R1.
#3.4: Setup Optional Web Interface
If you prefer a web-based interface in your browser:
Run the llama.cpp server:
llama-server.exe -m .\models\DeepSeek-R1-Distill-Llama-8B-Q8_0.gguf -ngl 33 --port 8080Open your browser and go to http://localhost:8080.
Start chatting with DeepSeek-R1 through the web UI.
For additional details on flags, performance tweaks, or other advanced usage, visit the llama.cpp GitHub page.
If you’d like to try the full (non-quantized) DeepSeek-R1 model, visit https://chat.deepseek.com/ and select “DeepThink (R1).”
By following these steps, you'll have DeepSeek-R1 running on your Vagon cloud desktop, providing a powerful AI toolset accessible from anywhere.
If you experience any issues, such as lagging or slower-than-expected performance while running DeepSeek-R1, it may be due to the resource requirements of your task. You can easily scale up to a higher performance tier on Vagon to access more powerful GPUs, additional CPU cores, and increased memory. Upgrading ensures smoother operation and optimal performance for resource-intensive workloads. Adjusting your plan can be done directly within your Vagon account settings for a seamless transition.
#6: Comparing DeepSeek-R1 on Serverless GPUs, Vagon Cloud Desktops, and Local Machines
When deciding where to run DeepSeek-R1, the choice of computing environment impacts performance, flexibility, and your overall workflow. Here’s a comparison of serverless GPUs, Vagon Cloud Desktops, and local machines—with an emphasis on why Vagon stands out as the optimal choice.
1. Serverless GPUs
Serverless GPUs, such as those offered by AWS Lambda or Google Cloud Functions, are designed for specific, short-term tasks. They are highly cost-efficient because you only pay for the resources you use, making them ideal for quick, one-off workloads. Additionally, serverless GPUs are fully managed by the provider, which eliminates the need for maintenance or manual server management.
However, serverless GPUs lack flexibility and are not suitable for iterative workflows or persistent environments. This limitation can make them challenging to use for tasks like developing AI models or running complex simulations. Furthermore, they are restrictive when it comes to running additional software or tools, such as code editors or AI code review tools, which are essential for holistic workflows. The setup process can also be complicated, as configuring environments and dependencies for each task often requires significant effort and expertise.
2. Vagon Cloud Desktops
Vagon Cloud Desktops provide a revolutionary approach by offering a high-performance, persistent environment that feels like your local machine but with significantly more power. One of their standout features is the ability to create a holistic workflow. Unlike serverless GPUs, Vagon allows you to seamlessly run additional tools like Visual Studio, Jupyter Notebooks, Excel, MATLAB, Blender, Unity, Unreal Engine, and even productivity apps like Slack or Google Chrome. This flexibility enables you to switch between tasks—such as running DeepSeek-R1 and analyzing results in Excel or coding in Visual Studio—without any interruptions.
The experience is akin to using a fully equipped Windows desktop, where you can install and manage software just as you would on a physical machine. Vagon also delivers unparalleled performance by letting you scale your resources on demand to handle anything from AI training to video rendering or 3D simulations. Furthermore, its accessibility from any device with an internet connection ensures you can work from anywhere, whether you're on a laptop, tablet, or smartphone. With no need to manage hardware or infrastructure, Vagon makes the process seamless and user-friendly.
The only notable downside of Vagon cloud desktops is their dependency on a stable internet connection. If your connection is unreliable, it may impact your experience, especially during high-intensity workloads.
3. Local Machines
Running DeepSeek-R1 on a local machine offers the advantage of low latency, as it eliminates any reliance on network connections. This means that responses and computations are immediate, ensuring smooth and uninterrupted performance. Additionally, local machines give you complete control over your setup, allowing you to configure hardware and software exactly as needed for your specific tasks.
However, the performance of a local machine is inherently limited by its hardware specifications. If your system lacks a powerful GPU, sufficient memory, or a fast processor, it may struggle to handle resource-intensive tasks such as AI model inference or 3D rendering. Building or upgrading a machine capable of running such tasks efficiently can also be prohibitively expensive, as high-end GPUs and components come with significant upfront costs. Lastly, local machines lack built-in scalability; once you hit the limits of your hardware, you cannot dynamically upgrade or expand resources to meet the demands of more complex projects.
Why Vagon Stands Out
Unlike serverless GPUs or local machines, Vagon offers a complete, holistic experience. You’re not limited to running just DeepSeek-R1; you can seamlessly integrate all your favorite tools into your workflow. For example:
Use Visual Studio to edit code.
Run Excel to analyze your results.
Use MATLAB or Jupyter Notebooks for advanced data analysis.
Vagon’s ability to combine powerful cloud computing with the familiarity of a local machine gives you a flexible, all-in-one workspace that no other solution can match.
If your project requires only short, simple tasks, serverless GPUs can be a budget-friendly option. Local machines are viable if you have powerful hardware and prefer offline access. However, Vagon cloud desktops stand out as the superior choice for running DeepSeek-R1 and beyond, offering:
Scalability for resource-heavy tasks.
A persistent, high-performance desktop environment.
Integration with your favorite tools for a holistic, streamlined workflow.
With Vagon, you don’t just get the power to run DeepSeek-R1—you gain a versatile, professional-grade workspace that adapts to all your needs. Whether it’s AI, design, engineering, or productivity, Vagon empowers you to work smarter, faster, and better.
Conclusion
Whether you’re a developer, researcher, or enthusiast, Vagon makes it easy to set up and run resource-intensive models like DeepSeek-R1 without the need for expensive hardware.
Vagon desktops are just like your local machine but with top-tier performance, allowing you to run not only AI tools but also your favorite apps with ease. From engineering, coding and simulation software like CAD tools and Visual Studio Code to creative apps like Blender, After Effects, Unreal Engine, Unity, and more, Vagon handles them all seamlessly.
With options to use the command-line interface or an intuitive web-based UI, you can tailor your workflow to your preferences. And if your projects demand more power, Vagon’s scalable performance tiers ensure you’re always equipped for the task at hand.
So, take the leap, explore, and unlock the full potential of these powerful tools and applications from anywhere in the world.
Frequently Asked Questions (FAQ)
1. What is DeepSeek-R1, and why is it popular?
DeepSeek-R1 is an advanced AI model designed for complex reasoning tasks like coding assistance, mathematical problem-solving, and natural language inference. Its open-source nature, efficient architecture, and cost-effectiveness make it a popular choice among researchers and developers looking for powerful AI solutions.
2. What are the hardware requirements for running DeepSeek-R1 locally?
To run DeepSeek-R1 locally, your machine needs a high-performance GPU (e.g., NVIDIA RTX 3090 or higher), at least 16 GB of RAM (32 GB recommended), and sufficient disk space for the model files. A multi-core CPU will also help improve performance.
3. Can DeepSeek-R1 be run on a CPU instead of a GPU?
Yes, but running DeepSeek-R1 on a CPU will significantly slow down its performance, especially for larger models. GPUs are highly recommended for resource-intensive tasks like training and inference due to their parallel processing capabilities.
4. Can I run DeepSeek-R1 on serverless GPUs?
Yes, but serverless GPUs, like those on AWS or Google Cloud, are generally designed for task-specific workloads. You’ll need to set up the environment each time you run the model, which can be tedious. Persistent environments, like cloud desktops, are more user-friendly for iterative workflows.
5. What is the difference between running DeepSeek-R1 on CLI and Web UI?
Command-Line Interface (CLI): Efficient for users comfortable with terminal commands. It’s faster and requires fewer resources.
Web UI: Offers a graphical interface that makes it easier to input prompts, tweak settings, and visualize outputs. It’s great for those who prefer an interactive experience.
6. Can I use multiple models with DeepSeek-R1?
Yes, you can download and switch between different models in the llama.cpp directory. Update the model path in your commands to use the desired model file.
7. How much disk space does DeepSeek-R1 require?
The disk space required depends on the size of the model you are using. For instance, the 4-bit quantized DeepSeek-R1 model file can range from 10 GB to 50 GB. Ensure you have enough free space before downloading the model.
Get Beyond Your Computer Performance
Run applications on your cloud computer with the latest generation hardware. No more crashes or lags.

Trial includes 1 hour usage + 7 days of storage.
Summarize with AI

Ready to focus on your creativity?
Vagon gives you the ability to create & render projects, collaborate, and stream applications with the power of the best hardware.

Vagon Blog



Run heavy applications on any device with
your personal computer on the cloud.
San Francisco, California
Solutions
Vagon Teams
Vagon Streams
Use Cases
Resources
Vagon Blog
How to Run Inkscape on a Cloud Ubuntu Desktop (2026 Guide)
How to Run Krita on a Cloud Ubuntu Desktop for Digital Painting (2026 Guide)
How to Run GIMP on a Cloud Ubuntu Desktop (2026 Guide)
How to Run Jupyter on a Cloud GPU Linux Desktop (2026 Guide)
Vagon vs GitHub Codespaces: Cloud Dev Environments Compared (2026)
Vagon vs RunPod: Which Cloud GPU Is Right for You? (2026 Comparison)
How to Watch Your AI Agent Work on a Cloud Ubuntu Desktop (2026 Guide)
How to Run a Local LLM on Ubuntu in the Cloud (2026 Guide)
How to Run Blender on a Cloud GPU (Ubuntu): The Complete 2026 Guide
Vagon Blog
Run heavy applications on any device with
your personal computer on the cloud.
San Francisco, California
Solutions
Vagon Teams
Vagon Streams
Use Cases
Resources
Vagon Blog
How to Run Inkscape on a Cloud Ubuntu Desktop (2026 Guide)
How to Run Krita on a Cloud Ubuntu Desktop for Digital Painting (2026 Guide)
How to Run GIMP on a Cloud Ubuntu Desktop (2026 Guide)
How to Run Jupyter on a Cloud GPU Linux Desktop (2026 Guide)
Vagon vs GitHub Codespaces: Cloud Dev Environments Compared (2026)
Vagon vs RunPod: Which Cloud GPU Is Right for You? (2026 Comparison)
How to Watch Your AI Agent Work on a Cloud Ubuntu Desktop (2026 Guide)
How to Run a Local LLM on Ubuntu in the Cloud (2026 Guide)
How to Run Blender on a Cloud GPU (Ubuntu): The Complete 2026 Guide
Vagon Blog
Run heavy applications on any device with
your personal computer on the cloud.
San Francisco, California
Solutions
Vagon Teams
Vagon Streams
Use Cases
Resources
Vagon Blog